
What does your benchmark actually measure?
Fighting bench-maxxing by asking: what maxxes your bench?

If you’re in the business of creating evals, you’re often told to make scores on your benchmark as low as possible at launch. For example, here are excerpts from How to Build Good Benchmarks by Ofir Press, one of the creators of SWE-Bench.

In this post, I argue minimizing scores at launch is the wrong frame to be in when creating a new benchmark, that hurts the whole benchmark ecosystem in the long-term. Instead, the frame that helps me more when interpreting and building new benchmarks is thinking of all possible ways one could maximize scores on my benchmark. Why? Because the community and models will rightfully try to. Eventually, they will find the simplest ways to improve scores on your benchmark. This has repeatedly turned out to NOT be the capability people thought the benchmark measures, which over time erodes trust in benchmarking as a whole.
What your benchmark actually measures is the simplest way to improve scores on it
It is common for benchmarks to be named after the capability they aspire to measure (e.g. SWE-Bench). Unfortunately, it is rare that 90% accuracy on Y-Bench reflects models succeed on 90% of Y tasks. This usually occurs due to two properties of the underlying data:
It consists of tasks which are easy to collect and fast to automatically verify. This is often a narrow slice of the overall capability. I think this is a practical compromise, and can be fixed by naming benchmarks more appropriately.
There are shortcuts, a term I use here as unintended strategies that improve scores without reflecting progress on the intended capability. This often happens due to fundamental issues with the benchmark design that are harder to mitigate.
I think benchmark developers can often identify both problems ahead of release by thinking about how models can be optimized for their benchmark. I find it useful to ask myself: If I trained a model on enough samples similar to my benchmark such that the resulting model scored 90% on the benchmark, what capabilities would emerge? More importantly, what would the resulting model not be able to do? Thinking about these questions should tell you what your benchmark is really measuring.
I will expand on the shortcuts problem, as it is much more subtle and thus pervasive. Take multiple choice evaluations. Models can sometimes answer samples accurately without even being shown the question. This doesn’t even have to be because of memorization or contamination, which is a shortcut the field has already come a long way in solving. In MCQs, the incorrect choices are often added artificially, and the correct choice can sometimes be inferred as the odd-one-out. Now, one could argue it is hard to know whether such shortcuts exist at the time of launch. This is where applying optimization pressure on your benchmark can help.
For example, last year we showed that by finetuning a linear classifier on language model embeddings given just the choices without the question, one can quantify (lower bound) the extent of choice-only shortcuts in popular MCQ benchmarks. Interestingly, you can correctly answer at least half of MMMU Pro, a “multimodal benchmark”, without the image! This finding was then corroborated across “multimodal” benchmarks. I think the shortcut problem only exacerbates as careless use of AI in evaluation designs increases.
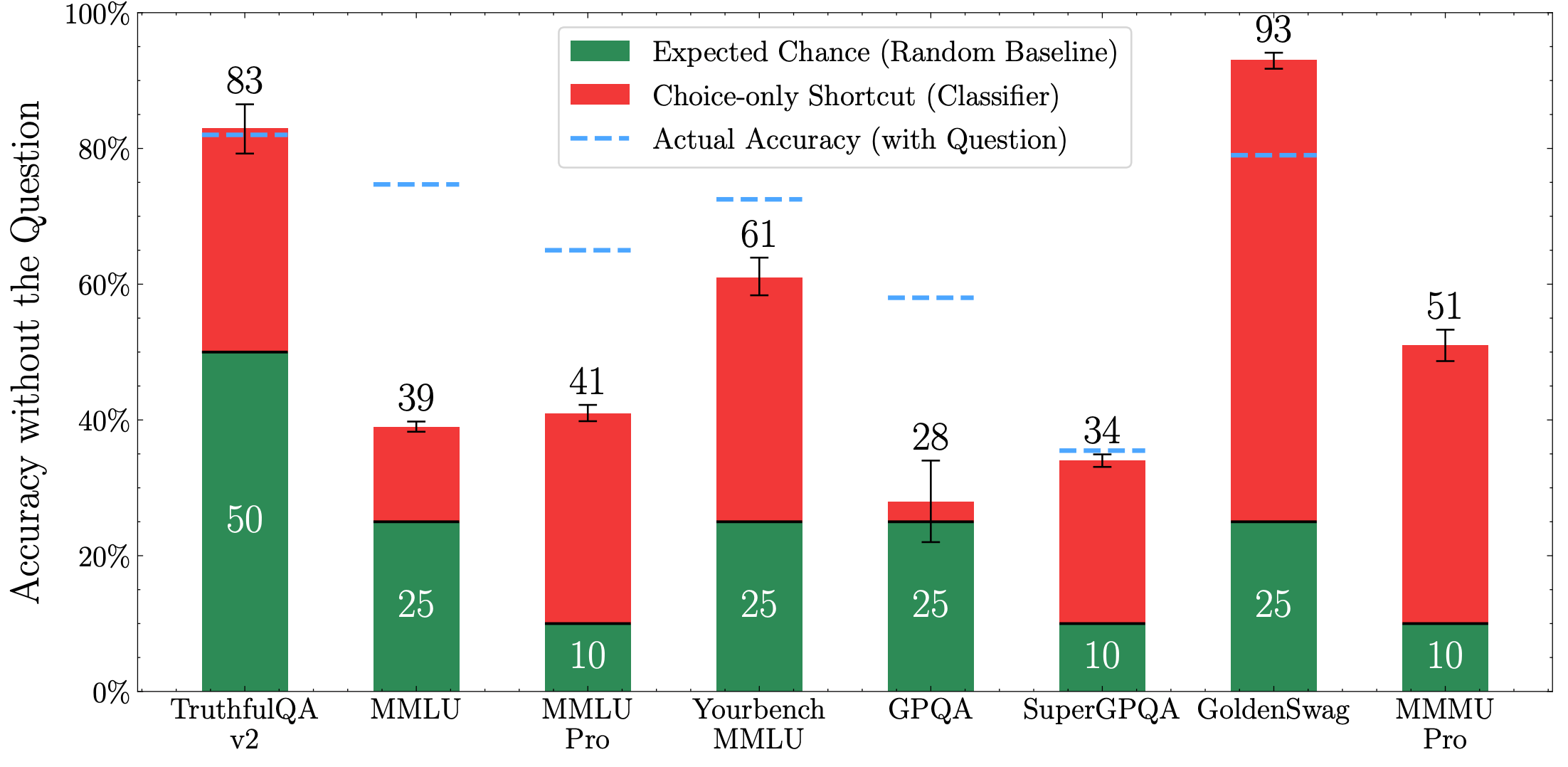
But not all hope is lost! The takeaway from the above example is: optimization pressure can reveal shortcuts in a benchmark, because it often finds the simplest path to improving scores. The GPQA paper adopts this strategy to remove problematic samples (see Appendix A.2), and is in my opinion a must-read for any eval creator to understand the level of care needed to make a great benchmark.
A common pushback I receive when I worry too much about shortcuts in benchmarks is: “If currently models don’t actually exploit them, how does it matter?”. This viewpoint makes sense if all you care about is model performance at launch.
But what if your launch is a success, and people actually start using your benchmark as a measure of progress? Both humans and deep learning like to find the least effort path to improving their objective, and this often ends up exploiting shortcuts. People start making inferences about which model is better at the intended capability, when one more could be exploiting the shortcuts more than the other. Even worse, they draw scientific conclusions about which methodologies work better from it. All these conclusions could be misled by the confounder of what is actually needed to improve on your benchmark. For example, ARC Is a Vision Problem showed how ARC-AGI 1 didn’t really need reasoning. Anthropomorphic Misalignment Research Needs Stronger Evidence provides a recent review of similar issues in safety evaluations. Another excellent example is Solving Spatial Supersensing Without Spatial Supersensing.
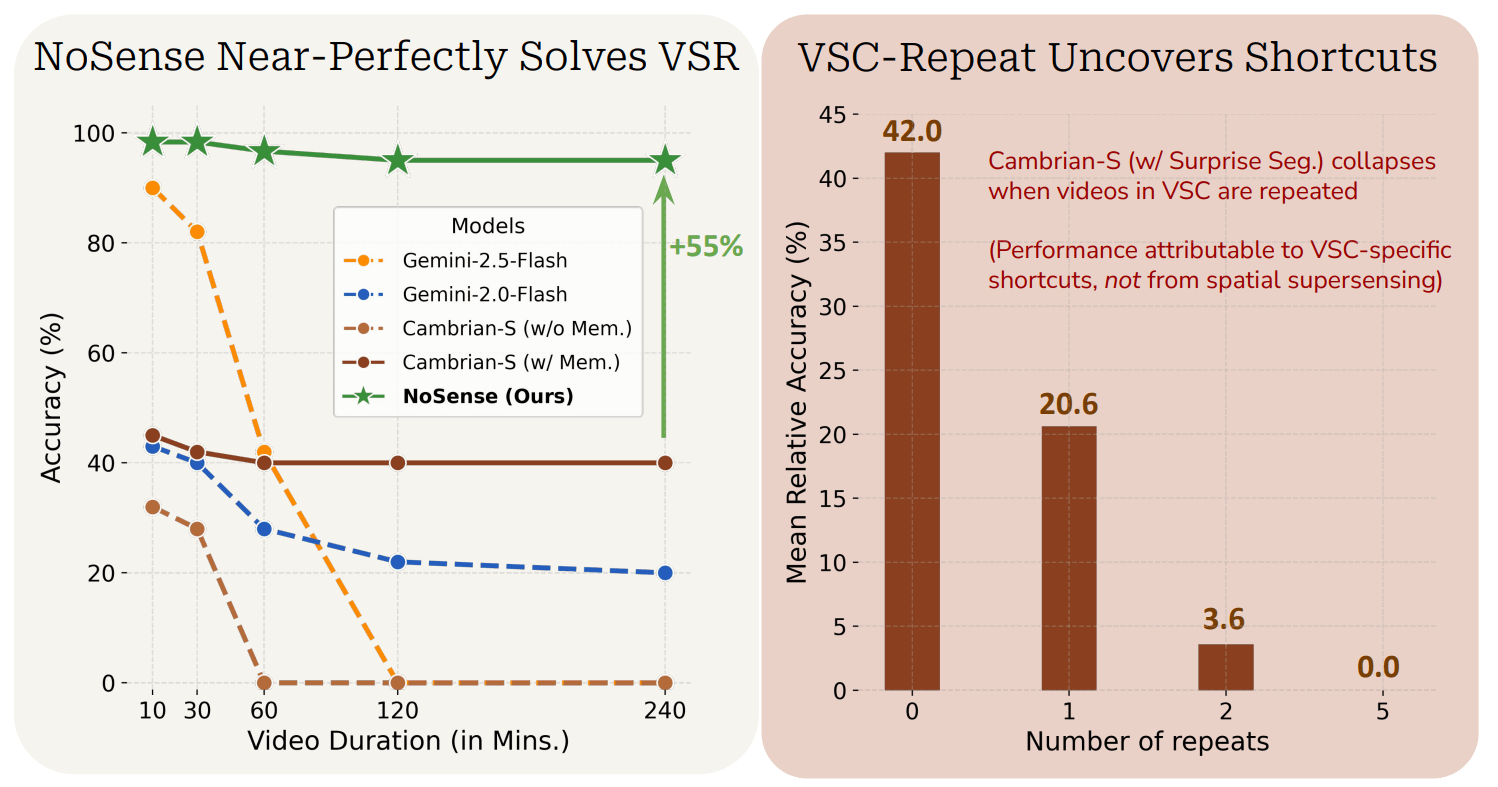
MMMU Pro, ARC AGI 1, VSI Super etc. are not the last evaluations that turn out to have shortcuts. An interesting new example is PostTrainBench, which aims to measure progress toward recursive self improvement via automating AI research. The setup is elegant: given 10 hours on 1 H100 and access to the web, to what score can frontier agents finetune 1-4B base models on each task individually?
As with any benchmark, my first thought when I heard about it was: what is needed to increase scores on this task? It is quite hard to RL or Self-Distill a 4B model on 1 H100, that too in 10 hours. In fact, improving on tasks like HealthBench and ArenaHard Writing in this way requires access to a judge during training, which is hard to co-locate on 1 H100 (API keys are not provided by design). So really, SFT on reasoning traces from stronger models (often available on HuggingFace), aka distillation, seems to be the most promising strategy. In its current form, a big factor in PostTrainBench performance is agents identifying the most recent strong model whose traces they can use for distillation. Indeed, this is the strategy Claude Opus 4.8 and GLM 5.2 take in most runs, the two best models on PostTrainBench as of writing. Distillation does not seem to be the capability PostTrainBench is interpreted to measure, and it can be considered a shortcut as relying on stronger models is not possible for post-training at the frontier, or self-improvement. This is just one example for how reasoning about how to optimize scores on the benchmark can help better interpret new benchmarks, and predict problems that might only surface later in actual benchmark runs.
Minimizing scores under optimization is a better objective than minimizing scores at launch
Another good example is how minimizing scores at launch leads to problematic approaches like filtering samples a baseline solves during benchmark development:

Here is why this strategy can mislead: Suppose you evaluate a frontier model on these samples, and only keep the 30% it gets wrong for your final benchmark. You launch your benchmark with 0% accuracy, and it goes on viral on Twitter for “LLMs can’t do X.” Thank you, Gary.
But what is the expected performance of a new model on this benchmark? Well, if we commit the grave sin of assuming samples are drawn independently from a distribution, and models don’t make correlated errors, it is exactly 70%. Now of course, we all know these assumptions don’t hold in practice. It could genuinely be that many of the 70% samples you filtered were fundamentally easier to solve given our current way of building models.
But even some effect of randomness could lead to faster growth in scores on your benchmark than improvement in underlying capabilities. Over time, when the whole benchmark ecosystem follows this practice, people become immune to large improvements on benchmarks, as they’ve learnt this doesn’t necessarily track their own experience. So please make sure you understand what makes the samples you keep harder than the ones you remove, and whether their difference is the capability you wanted your benchmark to measure. For progress on your benchmark is likely due to models improving at exactly this difference, and nothing more.
Note that none of this is in conflict with making hard benchmarks that act as a north star for the field to progress. In fact, fixing unintended shortcuts by anticipating them will delay when your benchmark gets saturated, extending its lifespan and impact! Indeed, Ofir’s blog was ahead of its time in pointing this out, but only in the Bonus and other guidelines section, which seems to get overlooked today:



These are all instances of thinking about what will happen when your benchmark is put under optimization pressure. I think this framing is more important than ever before because we now have way more ammunition to “bench-maxx”, such as prompt-optimization, RL, synthetic training data, and autoresearch. For example, RL and autoresearch are increasingly revealing reward hacks in benchmarks. Sometimes, even realistic prompts and official harnesses are enough to show how released papers of “hard benchmarks” underestimate performance. If a few lines of prompting can saturate scores on your benchmark, it is not hard. I’ve often heard reactions like “but we want to measure model performance out of the box, not with prompt/harness engineering”. Well, then your benchmark is one step of context distillation away from being rendered irrelevant.
The good news is, benchmark creators can use these tools to identify and remove unintended shortcuts that can improve scores on their benchmark without progress on the capabilities they set out to measure. In my own experiences with creating datasets, I have found optimizing harnesses, or even training small models extremely valuable, because the output traces of the resulting model often reveal shortcuts in the dataset that I had not expected. Recently, I even had success simply asking Codex to find shortcuts in data we created for an ongoing project, which led us to re-think how we build the evaluation entirely.
Of course, in the end one cannot find every possible confounder, and we all have bounded time and resources. It is also true that even if all benchmarks are broken, some are useful. My only point is that we can increase usefulness by spending reasonable amounts of effort ruling out shortcuts, and using tools available to those who will hill-climb our benchmark. A great idea is to consult domain experts, especially those who work on improving models at similar tasks, and asking them to steelman whether there are simpler ways to improve on the benchmark than you thought. Even giving your benchmark code and data to a coding agent and asking it what strategies and exploits can be used for hill-climbing is a good starting point.

Conclusion
Benchmark developers should not only care about what their benchmark will be perceived as at launch, but also whether it will genuinely reflect progress on capabilities people thought it measures, once the community and models start optimizing against it. This means not taking any potential problems lightly, even if they don’t occur today. Graduate and gradient descent will eventually exploit them! We should try our best to prevent misinterpretations from the evals we release, by anticipating pitfalls and explicitly highlighting them. Finally, you can help the community help you find unanticipated problems, by open-sourcing not only the code and datasets, but also visualized traces of new models you evaluate.
I thank Nikhil Chandak, Albert Catalan-Tatjer, Maksym Andriuschenko, Ameya Prabhu, Akshit Sinha, and Alexander Panfilov for helpful comments. All mistakes are mine, and opinions here don’t reflect the views of my employers.