

Some bits of information matter more than others. This observation is simple, yet has major implications for both exploration and learning. In humans, and AI.
Take the simple example of trying to estimate a large number. If its a number in the hundreds, it only matters if you got the hundreds place right. And the hundreds place matters millions of times less as the number nears a billion.
And yet, we worry too much about the number of bits of information. This is too linear a view. When it comes to real-world uncertainty, the higher order bits matter exponentially more. A detailed history of Donald Trump’s favourite car make, that’s thousands of bits. Who cares? Is he the US President? Now that one bit can change the world.
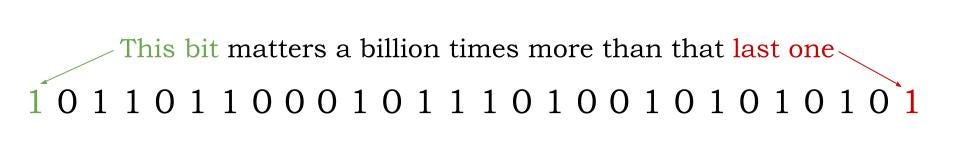
Implication for Making Decisions
For some time, I’ve been trying to use this principle to guide my research. In research, there are very many interesting questions—an endless list of phenomena yet to be explained. However, some questions are more important than others. These are the higher order bits. Given you, my reader, have finite time, these are the ones you should desperately prioritize. Don’t buy it from me? Take it from Richard Hamming. You and Your Research is perhaps the most important lecture a researcher can watch.
“If you do not work on an important problem, it’s unlikely you’ll do important work.”
In a funny coincidence, the “Hamming Distance” itself measures the opposite, which interestingly brings me to… AI.
Implication for AI
Consider Imitation vs Reinforcement Learning (RL)—perhaps the biggest question in AI right now. LLM RL learns from scalar rewards, a small number of bits of information in comparison to Supervised Finetuning (SFT), which imitates full sentences. On the surface, the latter is far more “information-dense”. Indeed, John Schulman’s excellent new blogpost shows we need to change a small number of bits in an LLM to achieve the huge improvements we’ve seen from RL. Why could this be? Does this mean RL is less important for LLM learning?
No. You see, SFT, in a way, minimizes the hamming distance to a reference answer. For SFT, each bit of difference matters equally. Potato, potahto? For SFT, it means the world. On the other hand, RL? It only cares about whether you succeeded or not, no matter how. That’s the highest order bit, the important one. The one that SFT would be willing to sacrifice to correctly imitate speling1.
And that my friends is the power of RL over imitation in the limit. It supervises the highest order bit, and saves you the cost of collecting the less important ones.
1 Of course, SFT is still important when you *do* care about all bits, such as when gathering “knowledge”. In that case, RL may be too inefficient. Contrary to what this post may have you believe, I am not an RL “Maximalist”.