
How to game the METR plot
Unpacking AI's favourite exponential curve of 2025

TL;DR: In 2025, we were in the 1-4 hour range on the METR plot, which has only 14 samples. The topic of each sample is public, making it easy to game METR horizon length measurements for a frontier lab, sometimes inadvertently. Finally, the “horizon length” under METR’s assumptions might be adding little information beyond benchmark accuracy. None of this is to criticize METR—its not possible to be perfect in a first release. But I’m tired of what is being inferred from this plot, pls stop!
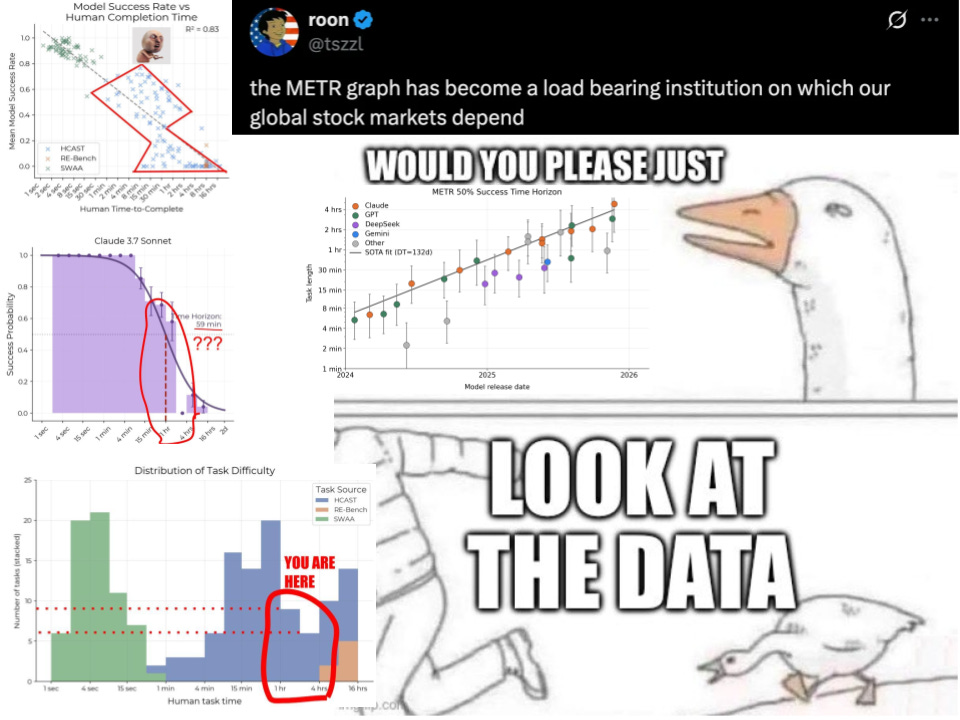
14 prompts ruled AI discourse in 2025
The METR horizon length plot was an excellent idea: it proposed measuring the length of tasks models can complete (in terms of estimated human hours needed) instead of accuracy. I'm glad it shifted the community toward caring about long-horizon tasks. They are a better measure of automation impacts, and economic outcomes (for example, labor laws are often based on number of hours of work).
However, I think we are overindexing on it, far too much. Especially the AI Safety community, which based on it, makes huge updates in timelines, and research priorities. I suspect (from many anecdotes, including roon’s) the METR plot has influenced significant investment decisions, but I’ve not been in any boardrooms.
Here is the problem with this. In 2025, according to this plot, frontier AI progress occurred in the regime of horizon length between 1 to 4 hours.
Guess how many samples have 1-4hr estimated task lengths in the METR data?
Just 14. How do we know? Kudos to the authors, the paper has this information, and they transparently provide task metadata.
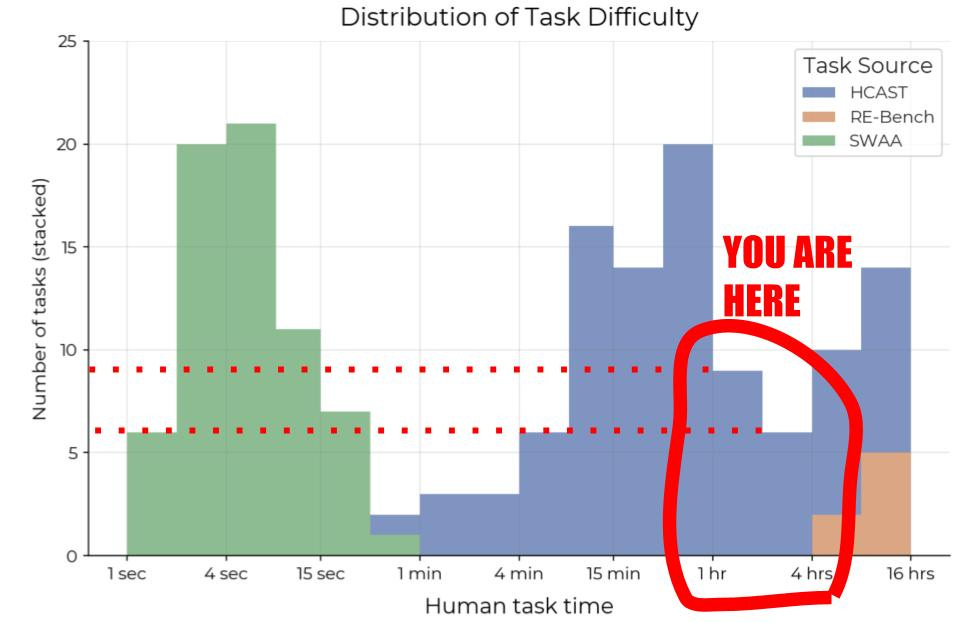
Hopefully, for many, this alone rings alarm bells. Under no circumstance should we be making such large inferences about AGI timelines, US vs China, Closed vs Open model progress, research priorities, individual model quality etc. based on just 14 samples. An early sign of this problem was there when the original METR paper was released in March 2025. The best performing model at the time, Claude 3.7 Sonnet, was estimated to have a horizon length of 59 mins. Now see its success rate distribution over task lengths:
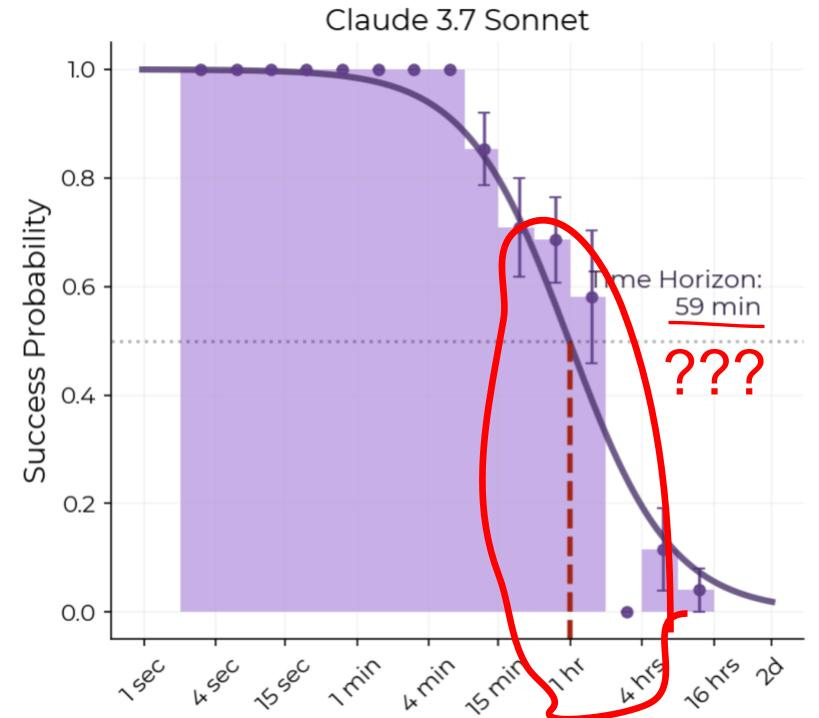
Notice how the model has almost a 60 ± 15% probability of success on 1-2hr tasks. So why is the estimated 50% success horizon length 59 minutes?! Because it doesn’t get anything right in the 2-4 hr range. METR calculates the horizon length by fitting a logistic curve to individual sample outcomes, like the dark purple line above. Notice how 0% on the 2-4hr range leads to a very bad logistic fit (the curve is below the 95% confidence interval for 0.5-1hr, and 1hr-2hrs range). We’ll come to my skepticism arising from the core modelling assumption, of using a logistic curve, later. My suspicion is Claude 3.7 Sonnet has 0% success in the 2-4hr range because they only had 6 samples for that range, most of which were from cybersecurity capture the flag contests. Cyber is considered a dual-use, safety hazard capability in WMDP, which labs were careful about in early 2025. Remember, this is Anthropic.
To improve METR horizon length, train on cybersecurity contests
I promised you there’s a way to game the horizon length on the METR eval. Here’s how. The samples in the 1 minute to 16 hour range mostly come from HCAST. It turns out HCAST transparently tells us what each of these tasks are about.

Why is this a big deal? Well, if you know what topic you want to improve performance on, its not that hard to do so. You can create targeted synthetic data, or just hire vendors like Scale, Mercor and Surge to upsample such tasks in your post-training mix. If you notice, most of the tasks in this range are Cybersecurity CTFs, and MLE tasks. OpenAI has been explicit about specifically targeting these capabilities for recent Codex models:
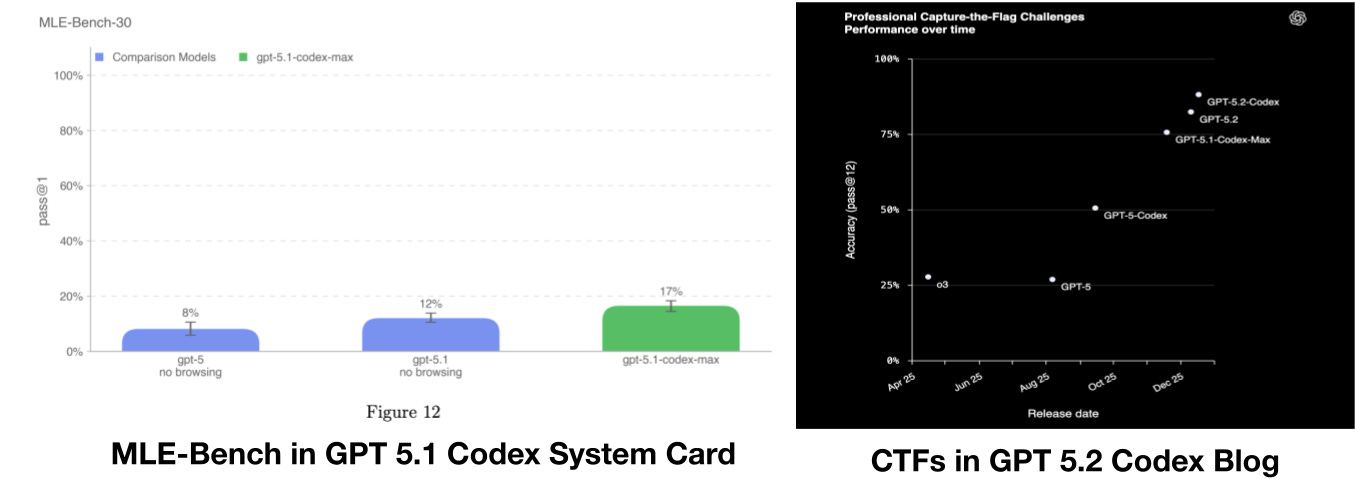
Now, I’m not saying the labs are training on MLE and Cybersecurity data to game the METR plot. They probably have other incentives to improve on them. But this is precisely why the METR plot is unlikely to generalize, it measures exactly what US labs are focusing on! If Kimi, or DeepSeek, want to shoot past, they can just collect a lot of ML-Training and Cybersecurity prompts, and finetune on them.
Note that given there are only 14 samples in the relevant task length range, getting even 1 or 2 extra samples right significantly increases horizon length! It probably increases even more if you get the longer tasks (8h+, from RE-Bench right), by luck or overfitting, as today’s Claude 4.5 Opus result showed us. In fact, perhaps because Anthropic doesn’t want to risk training on cybersecurity, we still have low accuracy in the 2-4hr range?

HCAST Accuracy alone predicts log-linear trend in METR Horizon Lengths
Finally, lets look at how METR estimates 50% success horizon length. They assume a logistic relation between the probability of success, and gap between the horizon length (estimated variable) and task length:
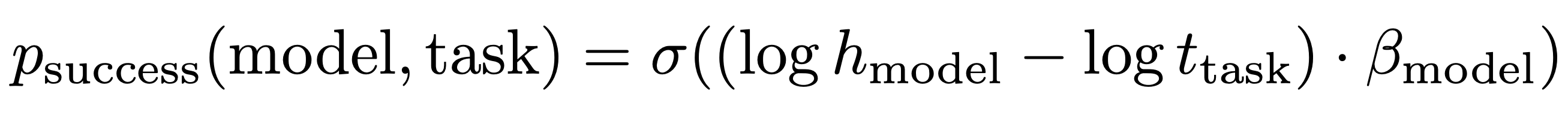
You infer h (the 50% horizon length) by fitting the 0/1 success evaluation data of each task. β is also a learnt parameter, governing the slope of how fast the logistic function falls from 1 to 0.
I think once you assume a logistic function, its almost guaranteed that if a new model solves one additional task, it’s going to continue the log-linear trend. Remember that METR also only adds more models to the point when they think they are likely to push the frontier. Coupled with measuring on a task distribution that model developers are actively trying to improve on, I think the log-linear trend, or X month doubling period, pops out almost tautologically from the logistic fit assumption.
For example, I tried deriving the horizon length from JUST their reported accuracy, without looking at individual sample evaluations at all. Remember how the main contribution of the METR plot was shifting focus from aggregate accuracy to horizon lengths? Well it turns out, if you use the aggregate accuracy, and the task length distribution, and fit the logistic function to estimate horizon length assuming even a constant β=0.7, you recover the log-linear trend:
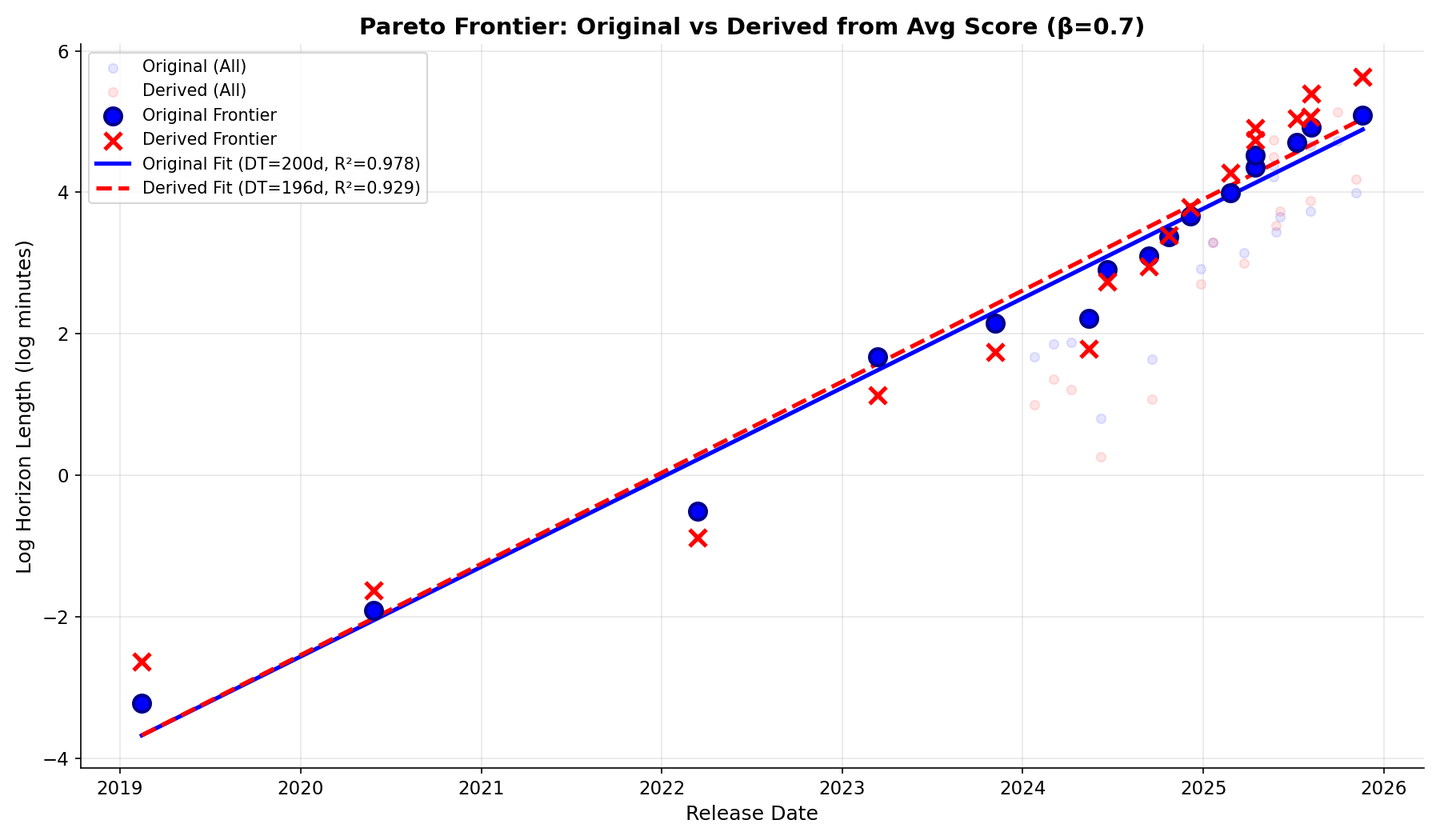
This means, if you had access to just the aggregate accuracy on HCAST, you could estimate the horizon length without knowing which samples the model gets right or wrong. It could be wrong on the short ones, and right on the long ones, for all you care.
Now presumably this logistic fit assumption arises from an earlier plot in the paper, claiming model success rates go down linearly with doubling in task length. I have a qualm with this plot too:
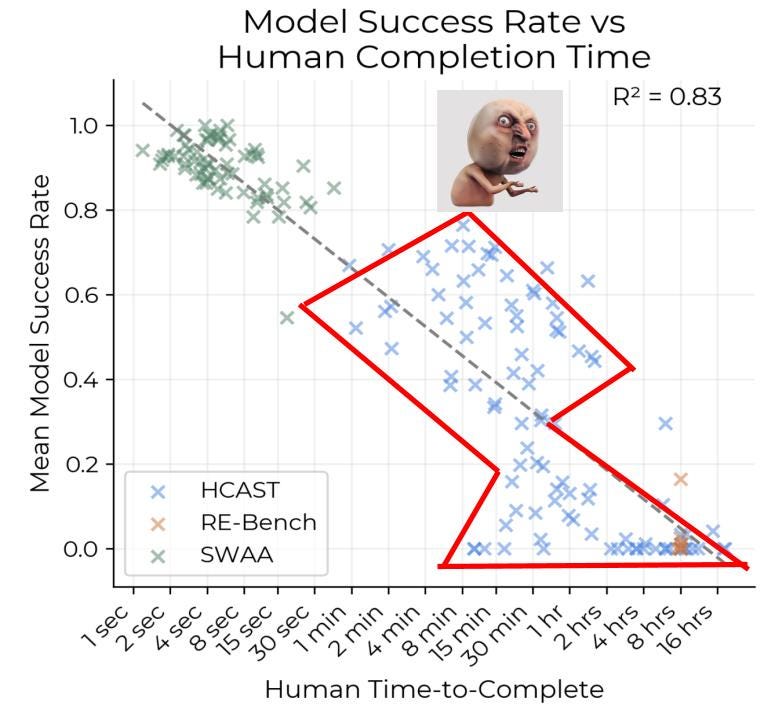
Notice how the log-linear fit here only looks good for the SWAA data, in the 1 sec - 1 min range. There’s something completely different going on for tasks longer than 1 minute, clearly not explained by the log-linear fit. If you tried to make a best fit line on the blue points (the length of tasks we care about after 2024), you’d get a very different, almost vertical line, with a very low R^2. I don’t know how load-bearing this is on the use of a logistic function to fit p(success) vs task length when estimating horizon lengths.
I am not a statistician, so I am uncertain about this final part of the analysis. I don’t know what it implies. I don’t know how problematic it is to assume a logistic function for this data. It’s hard to say for sure, as, for subsequent models after Claude 3.7 Sonnet, they didn’t release data to compute the success rate vs task length distribution. I invite people more experienced than me in statistics to look into this, because it seems a bit suspicious.
 on X")
Overall, I wish we had more, and robust measurements for model horizon lengths. I think it is a much more meaningful metric than accuracy. Heck, I even wrote a paper on this topic. I applaud METR for turning my, and many others’ attention towards this. But the way people are misinterpreting, and making wild inferences from the headline horizon length numbers METR puts out every month, worries me. If we are staking investment decisions, and research priorities based on an evaluation, it needs to be really robust. And making robust long-horizon benchmarks is hard, expensive, and uncharted territory. I hope METR plot v2 rises to the challenge!
I thank Sumeet Motwani, Ameya Prabhu, Arvindh Arun, and Akshit Sinha for feedback on this post. I appreciate folks at METR recognizing the value of these critiques when I tweeted about them.
this was a very useful intuition check for me
Thanks for the write-up.